Provides solution for enhancing the workflow of clustering analyses and ggplot2-based elegant data visualization. Read more: Visual enhancement of clustering analysis.
eclust(
x,
FUNcluster = c("kmeans", "pam", "clara", "fanny", "hclust", "agnes", "diana"),
k = NULL,
k.max = 10,
stand = FALSE,
graph = TRUE,
hc_metric = "euclidean",
hc_method = "ward.D2",
gap_maxSE = list(method = "firstSEmax", SE.factor = 1),
nboot = 100,
verbose = interactive(),
seed = 123,
...
)Arguments
- x
numeric vector, data matrix or data frame
- FUNcluster
a clustering function including "kmeans", "pam", "clara", "fanny", "hclust", "agnes" and "diana". Abbreviation is allowed.
- k
the number of clusters to be generated. If NULL, the gap statistic is used to estimate the appropriate number of clusters. In the case of kmeans, k can be either the number of clusters, or a set of initial (distinct) cluster centers.
- k.max
the maximum number of clusters to consider, must be at least two.
- stand
logical value; default is FALSE. If TRUE, then the data will be standardized using the function scale(). Measurements are standardized for each variable (column), by subtracting the variable's mean value and dividing by the variable's standard deviation.
- graph
logical value. If TRUE, cluster plot is displayed.
- hc_metric
character string specifying the metric to be used for calculating dissimilarities between observations. Allowed values are those accepted by the function dist() [including "euclidean", "manhattan", "maximum", "canberra", "binary", "minkowski"] and correlation based distance measures ["pearson", "spearman" or "kendall"]. Used only when FUNcluster is a hierarchical clustering function such as one of "hclust", "agnes" or "diana".
- hc_method
the agglomeration method to be used (?hclust): "ward.D", "ward.D2", "single", "complete", "average", ...
- gap_maxSE
a list containing the parameters (method and SE.factor) for determining the location of the maximum of the gap statistic (Read the documentation ?cluster::maxSE).
- nboot
integer, number of Monte Carlo ("bootstrap") samples. Used only for determining the number of clusters using gap statistic.
- verbose
logical value. If TRUE, the result of progress is printed.
- seed
integer used for seeding the random number generator.
- ...
other arguments to be passed to FUNcluster.
Value
Returns an object of class "eclust" containing the result of the standard function used (e.g., kmeans, pam, hclust, agnes, diana, etc.).
It includes also:
cluster: the cluster assignement of observations after cutting the tree
nbclust: the number of clusters
silinfo: the silhouette information of observations, including $widths (silhouette width values of each observation), $clus.avg.widths (average silhouette width of each cluster) and $avg.width (average width of all clusters)
size: the size of clusters
data: a matrix containing the original or the standardized data (if stand = TRUE)
The "eclust" class has method for fviz_silhouette(), fviz_dend(), fviz_cluster().
See also
Examples
# Load and scale data
data("USArrests")
df <- scale(USArrests)
# Enhanced k-means clustering
# nboot >= 500 is recommended
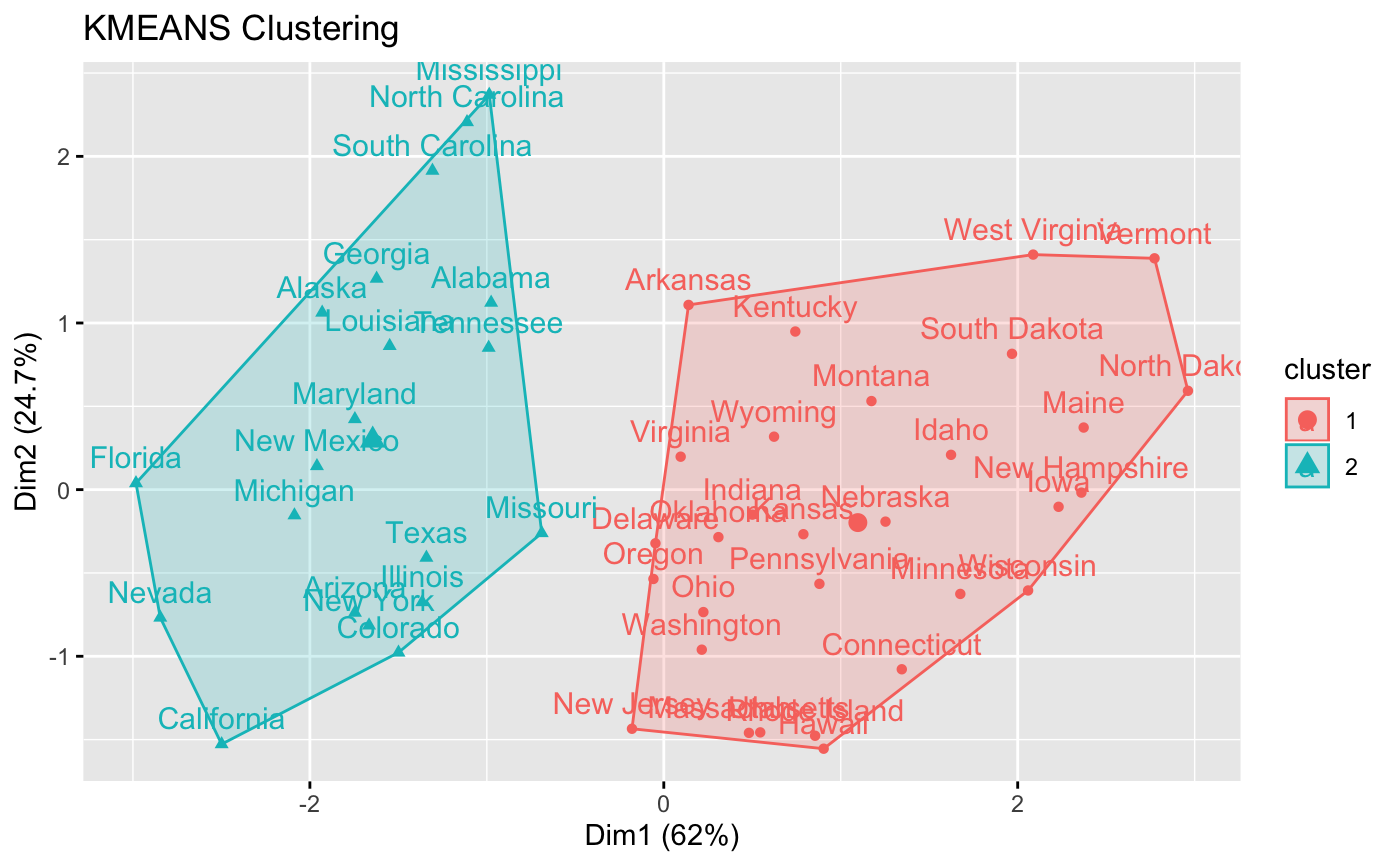
res.km <- eclust(df, "kmeans", nboot = 2)
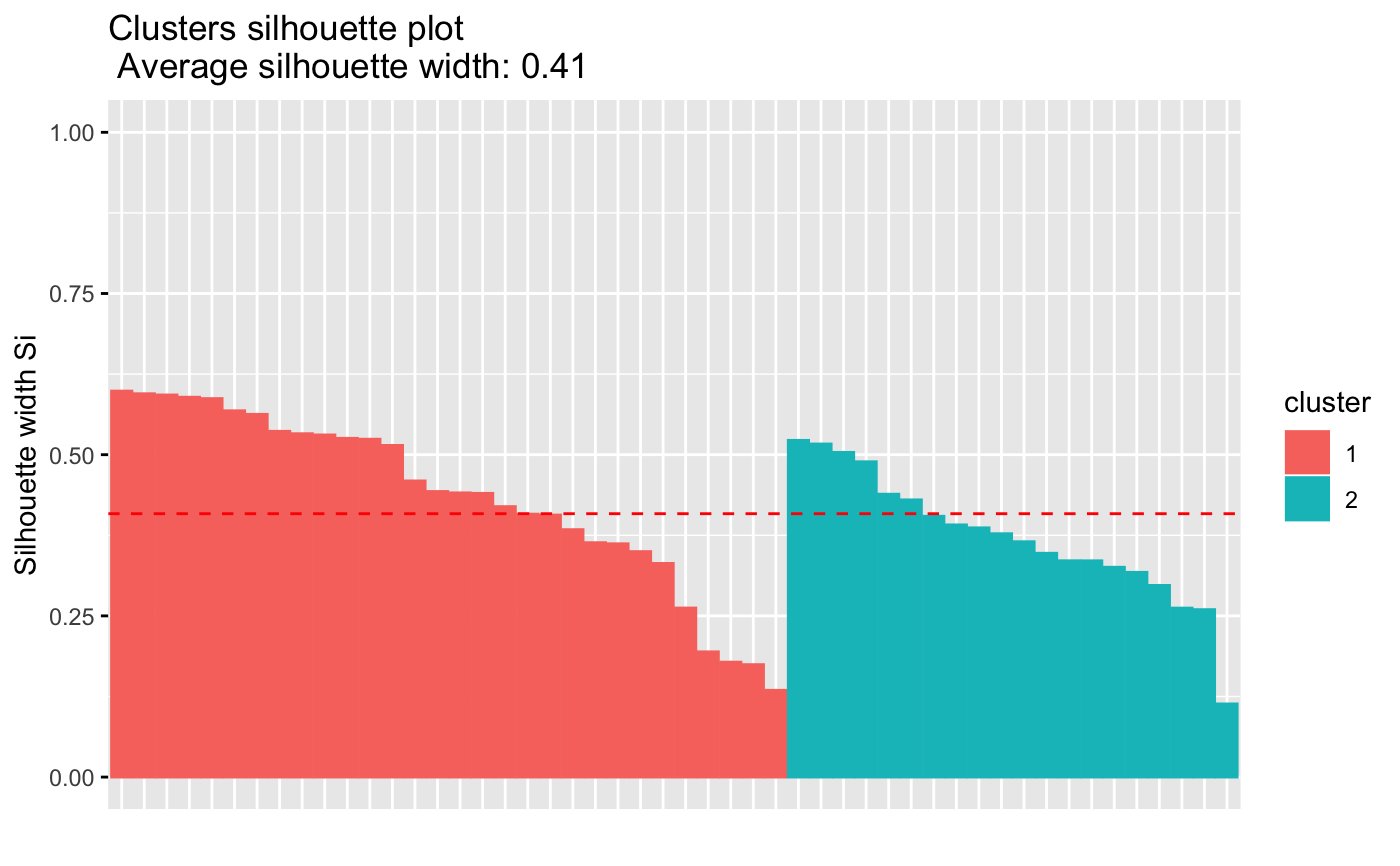
 # Silhouette plot
fviz_silhouette(res.km)
#> cluster size ave.sil.width
#> 1 1 7 0.27
#> 2 2 13 0.23
#> 3 3 11 0.39
#> 4 4 19 0.20
# Silhouette plot
fviz_silhouette(res.km)
#> cluster size ave.sil.width
#> 1 1 7 0.27
#> 2 2 13 0.23
#> 3 3 11 0.39
#> 4 4 19 0.20
 # Optimal number of clusters using gap statistics
res.km$nbclust
#> [1] 4
# Print result
res.km
#> K-means clustering with 4 clusters of sizes 7, 13, 11, 19
#>
#> Cluster means:
#> Murder Assault UrbanPop Rape
#> 1 -0.6958674 -0.5679476 1.12728218 -0.55096728
#> 2 -0.2162425 -0.2611064 -0.04793489 -0.06172647
#> 3 -1.1034717 -1.1654231 -0.99194587 -1.04874074
#> 4 1.0431796 1.0626143 0.19176752 0.85238754
#>
#> Clustering vector:
#> Alabama Alaska Arizona Arkansas California
#> 4 4 4 2 4
#> Colorado Connecticut Delaware Florida Georgia
#> 4 1 2 4 4
#> Hawaii Idaho Illinois Indiana Iowa
#> 1 3 4 2 3
#> Kansas Kentucky Louisiana Maine Maryland
#> 2 2 4 3 4
#> Massachusetts Michigan Minnesota Mississippi Missouri
#> 1 4 3 4 2
#> Montana Nebraska Nevada New Hampshire New Jersey
#> 3 2 4 3 1
#> New Mexico New York North Carolina North Dakota Ohio
#> 4 4 4 3 2
#> Oklahoma Oregon Pennsylvania Rhode Island South Carolina
#> 2 2 1 1 4
#> South Dakota Tennessee Texas Utah Vermont
#> 3 4 4 1 3
#> Virginia Washington West Virginia Wisconsin Wyoming
#> 2 2 3 3 2
#>
#> Within cluster sum of squares by cluster:
#> [1] 5.244931 10.860162 8.499862 45.263622
#> (between_SS / total_SS = 64.4 %)
#>
#> Available components:
#>
#> [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
#> [6] "betweenss" "size" "iter" "ifault" "clust_plot"
#> [11] "silinfo" "nbclust" "data" "gap_stat"
if (FALSE) { # \dontrun{
# Enhanced hierarchical clustering
res.hc <- eclust(df, "hclust", nboot = 2) # compute hclust
fviz_dend(res.hc) # dendrogam
fviz_silhouette(res.hc) # silhouette plot
} # }
# Optimal number of clusters using gap statistics
res.km$nbclust
#> [1] 4
# Print result
res.km
#> K-means clustering with 4 clusters of sizes 7, 13, 11, 19
#>
#> Cluster means:
#> Murder Assault UrbanPop Rape
#> 1 -0.6958674 -0.5679476 1.12728218 -0.55096728
#> 2 -0.2162425 -0.2611064 -0.04793489 -0.06172647
#> 3 -1.1034717 -1.1654231 -0.99194587 -1.04874074
#> 4 1.0431796 1.0626143 0.19176752 0.85238754
#>
#> Clustering vector:
#> Alabama Alaska Arizona Arkansas California
#> 4 4 4 2 4
#> Colorado Connecticut Delaware Florida Georgia
#> 4 1 2 4 4
#> Hawaii Idaho Illinois Indiana Iowa
#> 1 3 4 2 3
#> Kansas Kentucky Louisiana Maine Maryland
#> 2 2 4 3 4
#> Massachusetts Michigan Minnesota Mississippi Missouri
#> 1 4 3 4 2
#> Montana Nebraska Nevada New Hampshire New Jersey
#> 3 2 4 3 1
#> New Mexico New York North Carolina North Dakota Ohio
#> 4 4 4 3 2
#> Oklahoma Oregon Pennsylvania Rhode Island South Carolina
#> 2 2 1 1 4
#> South Dakota Tennessee Texas Utah Vermont
#> 3 4 4 1 3
#> Virginia Washington West Virginia Wisconsin Wyoming
#> 2 2 3 3 2
#>
#> Within cluster sum of squares by cluster:
#> [1] 5.244931 10.860162 8.499862 45.263622
#> (between_SS / total_SS = 64.4 %)
#>
#> Available components:
#>
#> [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
#> [6] "betweenss" "size" "iter" "ifault" "clust_plot"
#> [11] "silinfo" "nbclust" "data" "gap_stat"
if (FALSE) { # \dontrun{
# Enhanced hierarchical clustering
res.hc <- eclust(df, "hclust", nboot = 2) # compute hclust
fviz_dend(res.hc) # dendrogam
fviz_silhouette(res.hc) # silhouette plot
} # }